“우리는 최신 AI에게 똑같은 양식 문서를 읽히려고 비싼 값을 치르고 있다.” Netflix에서 일하는 엔지니어 Tejas Chopra가 한 말이다. 그는 자기가 만든 AI 서비스가 매번 똑같은 형식의 데이터를 AI에게 보내고 있다는 걸 발견했다. 파일 하나 검색하는 데 4만 단어어치 데이터가 들어갔는데, 그중 3만 5천이 거의 똑같이 반복되는 껍데기였다. 그래서 그는 주말에 도구 하나를 만들었다. 이름은 Headroom이다.
핵심 요약
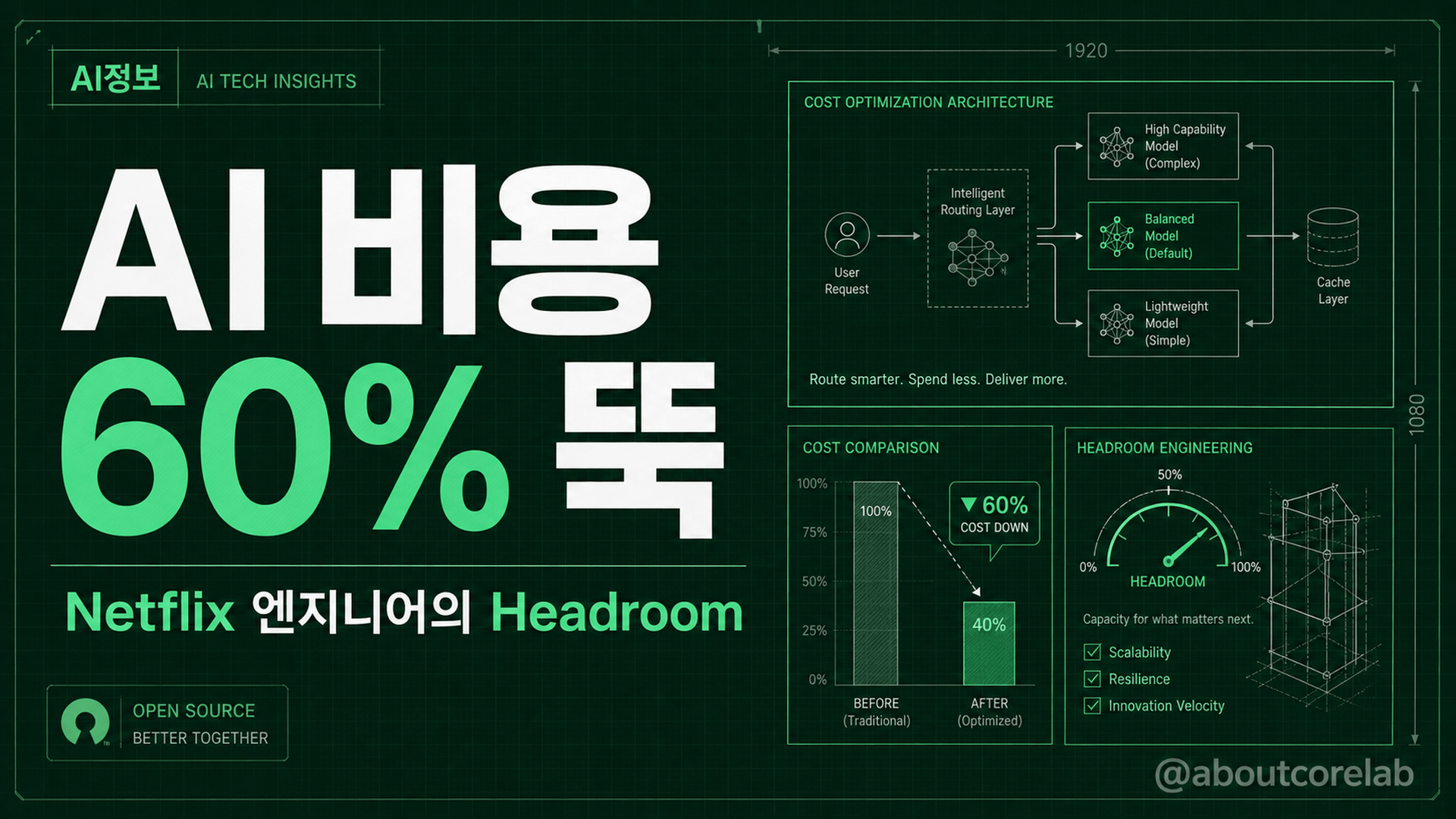
Headroom은 AI에 보내는 입력을 모델에 닿기 전에 60~95%까지 줄여 비용을 깎는 오픈소스다. Netflix 직원이 개인적으로 만들었고 Netflix 공식 제품은 아니다. 반복이 많은 데이터일수록 효과가 크고, 사람이 친 대화 같은 입력은 절감 폭이 작다.
Headroom은 공개되자마자 GitHub에서 별 4,400개 (GitHub)를 받으며 화제가 됐다. AI 비용에 골머리를 앓는 개발자가 그만큼 많다는 뜻이다. 그런데 이게 정확히 뭘 하는 도구이고, 정말 비용을 절반 넘게 깎아주는지, 아니면 또 하나의 과장된 약속인지 따져볼 만하다.

(Headroom 공식 저장소에 올라온 사용자별 누적 절감 토큰 리더보드, 출처: https://github.com/chopratejas/headroom)
AI에 글을 보낼 때마다 돈이 나간다
AI 서비스 요금은 글자 수에 거의 비례한다. ChatGPT 같은 서비스를 코드로 불러다 쓰면, AI에게 보내는 글과 AI가 돌려주는 글을 토큰(token, AI가 글을 잘게 쪼갠 단위. 한국어로 치면 글자나 단어 조각에 가깝다) 단위로 계산해 돈을 매긴다. 짧게 물으면 싸고, 길게 보내면 비싸다. 통화량에 따라 요금이 붙는 옛날 전화 요금제와 비슷하다.
문제는 회사가 만든 AI 서비스가 사람처럼 짧게 묻지 않는다는 데 있다. 예를 들어 코드를 짜주는 AI 비서는 질문에 답하기 전에 관련 파일, 검색 결과, 에러 기록을 잔뜩 끌어모아 AI에게 같이 보낸다. 배경 자료가 많을수록 답이 정확해지기 때문이다. 그런데 이 배경 자료에는 똑같은 형식이 끝없이 반복된다.
여기서 핵심 약어 하나만 짚고 가자. LLM(Large Language Model, 대규모 언어 모델)은 ChatGPT나 Claude처럼 글을 알아듣고 답하는 AI를 가리킨다. 앞으로 ‘AI’라고 쓰면 대부분 이 LLM을 뜻한다.
껍데기를 지우는 게 핵심이다
Headroom이 하는 일은 한 문장으로 정리된다. AI에게 보내기 직전에 입력을 압축한다. 사람이 쓰는 압축 프로그램이 사진이나 문서 용량을 줄이듯, Headroom은 AI에게 보낼 글의 용량을 줄인다. 단, 뜻은 그대로 둔 채 중복만 걷어낸다.
Chopra가 든 예시가 직관적이다. 데이터 100개를 AI에게 보낼 때, 보통은 100개 항목마다 “이름은 , 가격은 , 재고는 ___” 하는 형식이 100번 반복된다. 사람이라면 “아래 100개는 모두 이름·가격·재고 순서다”라고 한 번만 말하고 값만 나열한다. Headroom이 정확히 이걸 한다. 반복되는 형식을 한 번만 남기고 나머지는 값만 보낸다.
그래서 어떤 데이터를 보내느냐에 따라 절감 폭이 크게 갈린다. 제작자가 공개한 실측 표를 보면 차이가 뚜렷하다.
- 코드 검색: 90% 절감 (4만 5천 → 4천 5백)
- 기록 분석: 85% 절감 (2만 2천 → 3천 3백)
- 데이터베이스 조회: 85% 절감
- 긴 대화: 60% 절감 (8만 → 3만 2천)
앞의 세 개는 형식이 반복되는 기계 데이터다. 그래서 80~90% (DEV)가 깎인다. 반면 마지막 ‘긴 대화’는 사람이 친 문장이라 반복이 적고, 그만큼 덜 깎인다. 이 차이가 나중에 중요해진다.
90% 절감이라는 숫자, 어디까지 믿어야 하나
“비용 90% 절감”이라는 문구는 매력적이지만 전제를 빼면 오해를 부른다. 90%는 위에서 본 코드 검색처럼 똑같은 형식이 잔뜩 반복되는 경우의 숫자다. 일반 챗봇처럼 사람이 친 문장이 입력의 대부분이면 절감 폭은 훨씬 작다. 긴 대화가 60%에 그치는 것도 같은 이유다.
더 짚어둘 게 있다. Headroom이 누적 70만 달러 (The Register)(약 9억 원)를 아꼈다는 수치가 기사에 돈다. 그런데 이건 제작자가 자기 발표에서 밝힌 자기 보고 숫자다. 제3자가 따로 검증한 결과가 아니다. 솔직히 이런 절감 수치는 직접 자기 데이터로 켜보고 꺼봐서 비교하기 전엔 참고용으로만 봐야 한다.
그리고 Headroom은 Netflix가 공식으로 내놓은 제품이 아니다. Netflix 직원이 개인적으로 만들어 오픈소스로 공개했다. 일부 Netflix 팀이 비공식적으로 쓴다는 정도다. “Netflix가 만든 비용 절감 도구”라고 부르면 사실과 어긋난다. 만든 사람의 직장이 Netflix일 뿐이다.
코드 한 줄 안 고치고 붙일 수 있다
도입이 쉽다는 점은 인기 비결 중 하나다. Headroom은 AI 서비스와 진짜 AI 사이에 중간 정류장처럼 끼어든다. 우리 프로그램이 ChatGPT를 부르는 주소만 Headroom 쪽으로 바꿔주면, Headroom이 입력을 가로채 압축한 뒤 AI에게 넘긴다. 기존 코드는 건드릴 필요가 없다. 제작자 설명으로는 5분이면 붙는다.
압축이 위험해 보일 수 있다. 데이터를 줄였다가 AI가 중요한 정보를 놓치면 어쩌나 싶다. 그래서 Headroom은 줄인 원본을 잠깐 따로 보관한다. AI가 “이 부분 원본을 다시 보여달라”고 하면 되돌려준다. 짐을 압축해 부치되, 원본은 사물함에 잠깐 넣어두는 셈이다. 에러 기록이나 통계적으로 튀는 값처럼 함부로 지우면 안 되는 정보는 압축 대상에서 빼도록 설계돼 있다.
실제로 답의 정확도가 떨어졌는지도 측정값이 있다. 제작자 쪽 실측에서 코드 검색은 최대 90% (BrightCoding)까지 입력이 줄었다. 그러면서도 초등 수학 문제 풀이 정확도는 압축 전후 모두 0.870으로 변화가 없었다고 한다. 다만 이 측정 역시 제작자와 일부 제3자가 잰 것이고 독립 재현은 아직 부족하다. 결국 “내 서비스에서 답 품질이 유지되나”는 직접 확인해야 할 몫이다.
Headroom은 압축에 더해, AI 회사가 이미 제공하는 비용 절감 기능과도 손발을 맞춘다. 예를 들어 Anthropic은 똑같은 앞부분을 반복해서 보낼 때 그 부분을 재계산하지 않고 캐싱(caching, 한 번 처리한 결과를 저장해뒀다 재사용하는 방식)해 값을 깎아준다. Headroom은 보내는 글의 앞부분을 일정하게 맞춰 이 할인이 실제로 적용되도록 돕는다.

(Anthropic이 안내하는 프롬프트 캐싱 — 반복되는 앞부분을 재사용해 비용을 깎는 기능, 출처: https://docs.anthropic.com/en/docs/build-with-claude/prompt-caching)
어떤 사람이 쓰면 좋을까
Headroom이 모두에게 필요한 도구는 아니다. 효과는 입력에 반복되는 형식 데이터가 얼마나 많은가에 달렸다. 코드를 다루거나 서버 기록을 분석하거나 데이터베이스를 조회하는 AI 서비스를 운영한다면 효과가 클 가능성이 높다. 입력의 상당 부분이 기계가 뱉은 반복 데이터이기 때문이다.
반대로 사람과 자연스러운 대화를 주고받는 챗봇이 전부라면 기대만큼 안 깎인다. 사람 문장은 압축할 껍데기가 적다. 또 개인정보가 입력에 섞일 수 있는 서비스라면 주의가 필요하다. Headroom은 개인정보를 알아서 가려주지 않는다. 어떤 정보를 뺄지 직접 규칙으로 지정해야 한다.
비유하자면 Headroom은 모델을 바꾸는 도구가 아니라 짐을 싸는 방식을 바꾸는 도구다. 더 싼 항공권(저렴한 AI 모델)을 찾는 대신, 같은 비행기에 짐을 더 알뜰하게 싸서 추가 요금을 줄이는 쪽에 가깝다. 그래서 어떤 모델을 쓰든 같이 적용할 수 있다.
정리
Headroom이 던지는 메시지는 셋이다. AI 비용을 깎는 레버가 ‘더 싼 모델 찾기’ 하나뿐이 아니라 ‘입력 줄이기’로 하나 더 생겼다. 그 레버를 오픈소스가 무료로 쥐여준다. 단, 효과는 내 데이터가 얼마나 반복투성이인지에 달렸다.
그동안 AI 비용을 줄이려면 더 저렴한 모델로 갈아타는 게 거의 유일한 방법이었다. 모델 가격은 AI 회사가 정하니 우리가 손댈 여지가 없었다. Headroom 같은 압축 도구가 보여주는 건, 비용을 깎는 권한 일부가 모델을 만드는 회사에서 그걸 쓰는 사람 쪽으로 넘어온다는 점이다. 모델을 못 바꿔도 무엇을 보낼지는 내가 정할 수 있다.
물론 만능은 아니다. 90% 절감은 특정 조건에서의 숫자이고, 70만 달러 절감도 검증되지 않은 자기 보고다. 그래도 코드 한 줄 안 고치고 붙여 하루만 비교해보면 내 경우엔 얼마나 깎이는지 바로 나온다. AI 청구서가 부담스럽고 다루는 데이터에 반복이 많다면, 한번 켜보고 직접 재보는 것만으로 잃을 게 없는 실험이다.


