요즘 AI와 함께 글쓰기를 해보셨습니까? 정말 똑똑하지만 가끔은 “어? 이게 내가 원하던 느낌이 아닌데?” 하는 당황스러운 순간들이 있으셨을 것입니다. 특히 블로그 포스팅이나 보고서를 작성할 때, 문맥은 맞는데 뭔가 어투가 어색하거나, 내 의도와는 다른 방향으로 글이 흘러가는 경험 말입니다.
그런데 최근 Anthropic에서 출시한 클로드 오퍼스 4.1이 이런 아쉬움들을 상당 부분 해결해줄 수 있을 것 같습니다. 2025년 8월 5일에 공개된 이 새로운 모델은 단순히 성능만 좋아진 것이 아니라, 정말 사람다운 글쓰기와 코딩에서 엄청난 발전을 보여주고 있습니다.

클로드 오퍼스 4.1이 뭔가요? 정말 기존과 다른가요?
Q1. 클로드 오퍼스 4.1이 정확히 무엇인가요?
클로드 오퍼스 4.1은 기존 클로드 오퍼스 4의 업그레이드 버전입니다. 아주 간단하게 말씀드리면, 클로드가 더욱 똑똑해졌다고 보시면 됩니다. 특히 에이전트 작업, 실제 코딩, 그리고 추론 기능에서 눈에 띄는 향상을 보였습니다.
솔직하게 말씀드리면, 저는 그동안 클로드를 글쓰기에 주로 활용해왔습니다. 사람의 어투와 의견을 가장 잘 반영하고, 문맥에 맞게 글을 작성하는 데 정말 탁월했거든요. 스크립트나 블로그 글 작성할 때마다 클로드의 도움을 받곤 했는데, 이번 4.1 버전은 그런 강점이 더욱 강화된 것 같습니다.
Q2. 하이브리드 추론 모델이라고 하는데, 이게 뭔가요?
정말 흥미로운 부분입니다. 클로드 오퍼스 4.1은 ‘하이브리드 추론 모델’이라고 불립니다. 이것은 상황에 따라 빠르게 답할 수도 있고, 복잡한 문제일 때는 충분히 시간을 들여 깊게 생각할 수도 있다는 뜻입니다.
마치 우리가 간단한 질문에는 즉석에서 답하지만, 어려운 문제를 만나면 잠시 생각해보고 답하는 것과 비슷합니다. 클로드가 이제 ‘확장된 사고’라는 기능을 통해 최대 64,000토큰까지 깊게 생각할 수 있게 되었다고 합니다.
어떤 점들이 구체적으로 개선되었나요?
Q1. 코딩 성능이 얼마나 좋아졌나요?
정말 어마어마한 발전을 보였습니다. SWE-bench Verified라는 코딩 테스트에서 74.5%라는 최첨단 성능을 달성했습니다. 이 수치가 얼마나 대단한지 설명해보겠습니다.
실제로 GitHub에서는 “오퍼스 4에 비해 대부분의 기능에서 개선되었으며, 특히 멀티 파일 코드 리팩토링에서 뛰어난 성능을 보였다”고 평가했습니다. 즉, 하나의 파일이 아니라 여러 파일에 걸쳐 있는 복잡한 코드를 정리하고 개선하는 작업에서 탁월한 능력을 보여준다는 뜻입니다.
Q2. 디버깅 능력은 어떤가요?
라쿠텐 그룹에서 나온 평가가 정말 인상적입니다. “대규모 코드베이스 내에서 불필요한 조정이나 버그를 유발하지 않고 정확한 수정 사항을 찾아내는 데 탁월하다”고 했습니다.
이게 왜 중요하냐면, 기존 AI들은 버그를 고치겠다고 하다가 오히려 다른 부분에 새로운 문제를 만들어내는 경우가 많았거든요. 하지만 오퍼스 4.1은 정말 필요한 부분만 정확히 찾아서 고친다는 것입니다.
Q3. 전체적인 개발 능력은 얼마나 향상되었나요?
윈드서프라는 회사에서 측정한 결과에 따르면, 주니어 개발자 벤치마크에서 오퍼스 4에 비해 1 표준 편차 개선을 보였다고 합니다. 이는 소네트 3.7에서 소네트 4로의 도약과 유사한 수준의 성능 향상이라고 평가받고 있습니다.
쉽게 말해서, 이전 버전과 비교할 때 정말 큰 폭의 발전이 있었다는 뜻입니다.
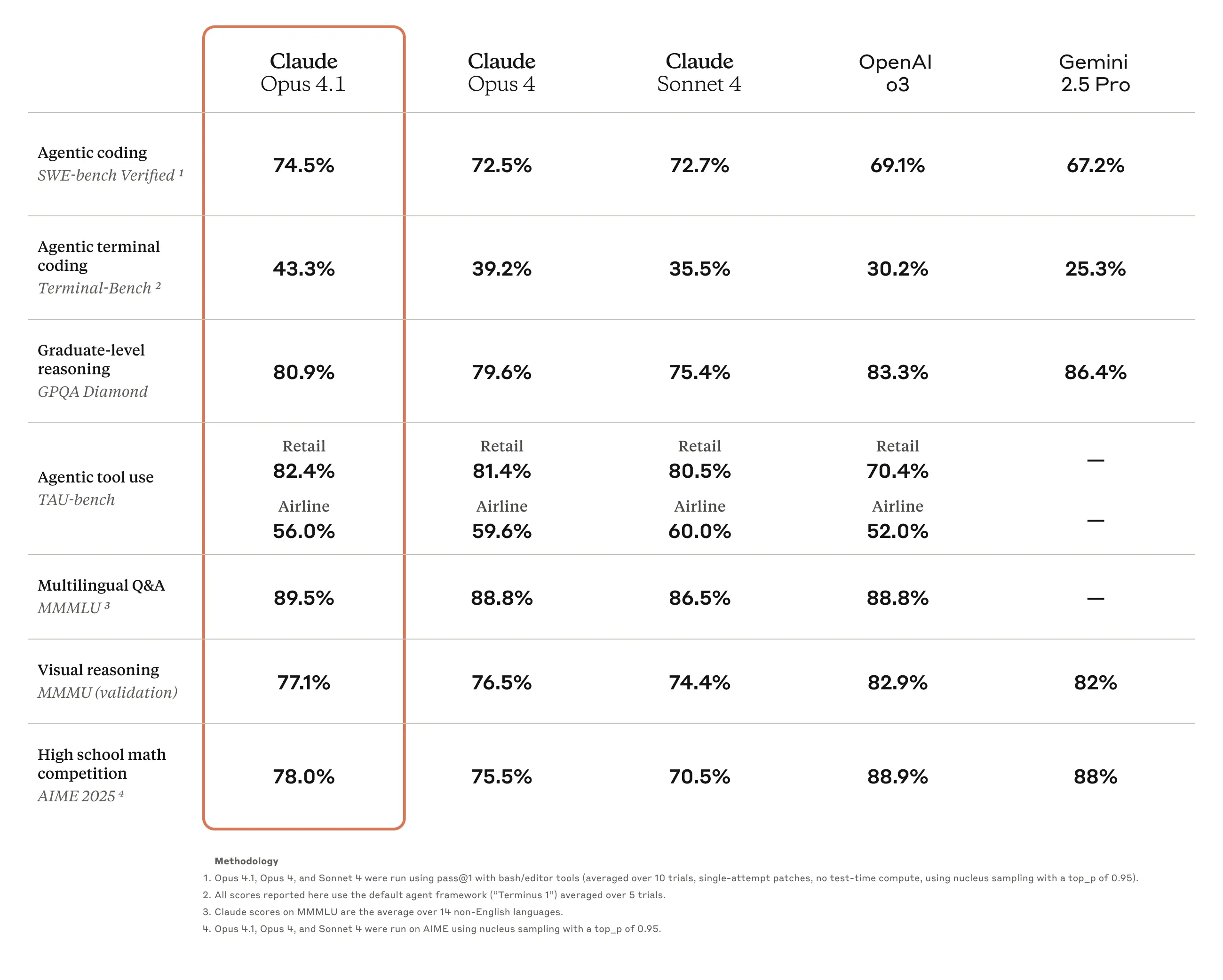
실제로 얼마나 좋아졌을까요? 벤치마크로 살펴보기
Q1. 어떤 기준으로 성능을 측정했나요?
Anthropic에서는 다양한 벤치마크를 통해 성능을 측정했습니다. 크게 두 가지 방식으로 나누어집니다:
확장된 사고 없이 측정한 것들:
- SWE-bench Verified (코딩 테스트)
- Terminal-Bench (터미널 작업 테스트)
확장된 사고를 활용해서 측정한 것들:
- TAU-bench (복잡한 추론 테스트)
- GPQA Diamond (과학 문제 해결)
- MMMLU, MMMU (종합적 이해력 테스트)
- AIME (수학 경시대회 문제)
Q2. TAU-bench에서는 어떤 방식으로 테스트했나요?
정말 흥미로운 방법을 사용했습니다. 클로드가 문제를 해결할 때 생각하는 과정을 별도로 기록하도록 했고, 더 많은 사고 단계를 허용했습니다. 최대 단계 수를 기존 30에서 100으로 증가시켰죠.
하지만 실제로는 대부분의 문제가 30단계 미만에서 해결되었고, 50단계를 넘긴 경우는 단 하나뿐이었다고 합니다. 즉, 더 깊게 생각할 수 있는 능력을 갖췄지만, 불필요하게 복잡하게 접근하지는 않는다는 뜻입니다.
어떻게 활용할 수 있을까요? 실용적인 접근법
Q1. 지금 바로 사용할 수 있나요?
네, 사용하실 수 있습니다! 유료 클로드 사용자라면 지금 당장 오퍼스 4.1을 경험해보실 수 있습니다. 또한 API를 통해서도 이용 가능하며, 아마존 베드록이나 구글 클라우드 버텍스 AI에서도 제공됩니다.
가격은 기존 오퍼스 4와 동일하다고 하니, 추가 비용 부담 없이 업그레이드된 성능을 누리실 수 있습니다.
Q2. 개발자가 아닌 일반 사용자도 혜택을 볼 수 있나요?
물론입니다! 저처럼 글쓰기에 AI를 활용하시는 분들에게는 정말 좋은 소식입니다. 더욱 정교해진 언어 이해력과 맥락 파악 능력은 블로그 포스팅, 보고서 작성, 기획서 작성 등 다양한 글쓰기 업무에서 큰 도움이 될 것입니다.
특히 복잡한 내용을 체계적으로 정리하거나, 독자의 입장에서 이해하기 쉽게 설명하는 작업에서 오퍼스 4.1의 향상된 추론 능력이 빛을 발할 것 같습니다.
Q3. API 사용자는 어떻게 접근하면 되나요?
개발자분들은 claude-opus-4-1-20250805라는 모델명을 사용하시면 됩니다. 기존 오퍼스 4에서 간단히 모델명만 변경하시면 바로 새로운 성능을 경험하실 수 있습니다.
앞으로 더 발전할 예정인가요?
Q1. 추가 업데이트 계획이 있나요?
Anthropic에서는 “수 주 내에 모델에 대한 훨씬 더 큰 개선 사항을 출시할 계획”이라고 밝혔습니다. 지금도 충분히 놀라운 성능 향상을 보여주고 있는데, 더 큰 개선이 예정되어 있다니 정말 기대가 됩니다.
Q2. 최근 다른 업데이트들도 있었나요?
네, 정말 활발한 업데이트가 이루어지고 있습니다:
- 2025년 9월 12일: 미국 CAISI 및 영국 AISI와 협력하여 안전 장치 강화
- 2025년 9월 11일: 직장 내 팀을 위한 메모리 기능 도입
- 2025년 9월 9일: 클로드가 파일을 생성하고 편집할 수 있는 기능 추가
특히 파일 생성 및 편집 기능은 글쓰기나 문서 작업을 하시는 분들에게 정말 유용할 것 같습니다.
마무리: AI와 함께하는 창작의 새로운 시대
클로드 오퍼스 4.1은 단순한 성능 업그레이드를 넘어서, AI와 인간이 협업하는 방식 자체를 바꿀 수 있는 가능성을 보여주고 있습니다. 특히 글쓰기나 코딩처럼 창의성과 논리성이 동시에 요구되는 작업에서 정말 든든한 파트너가 될 것 같습니다.
솔직히 모든 AI와 마찬가지로 아직 완벽하지는 않을 것입니다. 하지만 지금까지의 발전 속도를 보면, 머지않아 우리가 상상했던 것보다 훨씬 더 자연스럽고 효과적인 AI 협업이 가능할 것 같습니다.
AI에 관심 있으신 분들이라면, 지금이 바로 클로드 오퍼스 4.1을 경험해보기에 좋은 시점인 것 같습니다. 여러분만의 활용법을 찾아보시고, 더욱 창의적이고 효율적인 작업 환경을 만들어보시길 바랍니다.


