안드레 카파시(Andrej Karpathy)가 4월 3일에 올린 글 한 편이 개발자 커뮤니티를 뒤흔들었다. “최근 토큰 소비량의 대부분이 코드 조작이 아닌 지식 조작으로 이동했다.” vibe coding을 만든 사람이 코딩 이야기를 멈추고 위키 이야기를 시작한 것이다.
핵심 요약
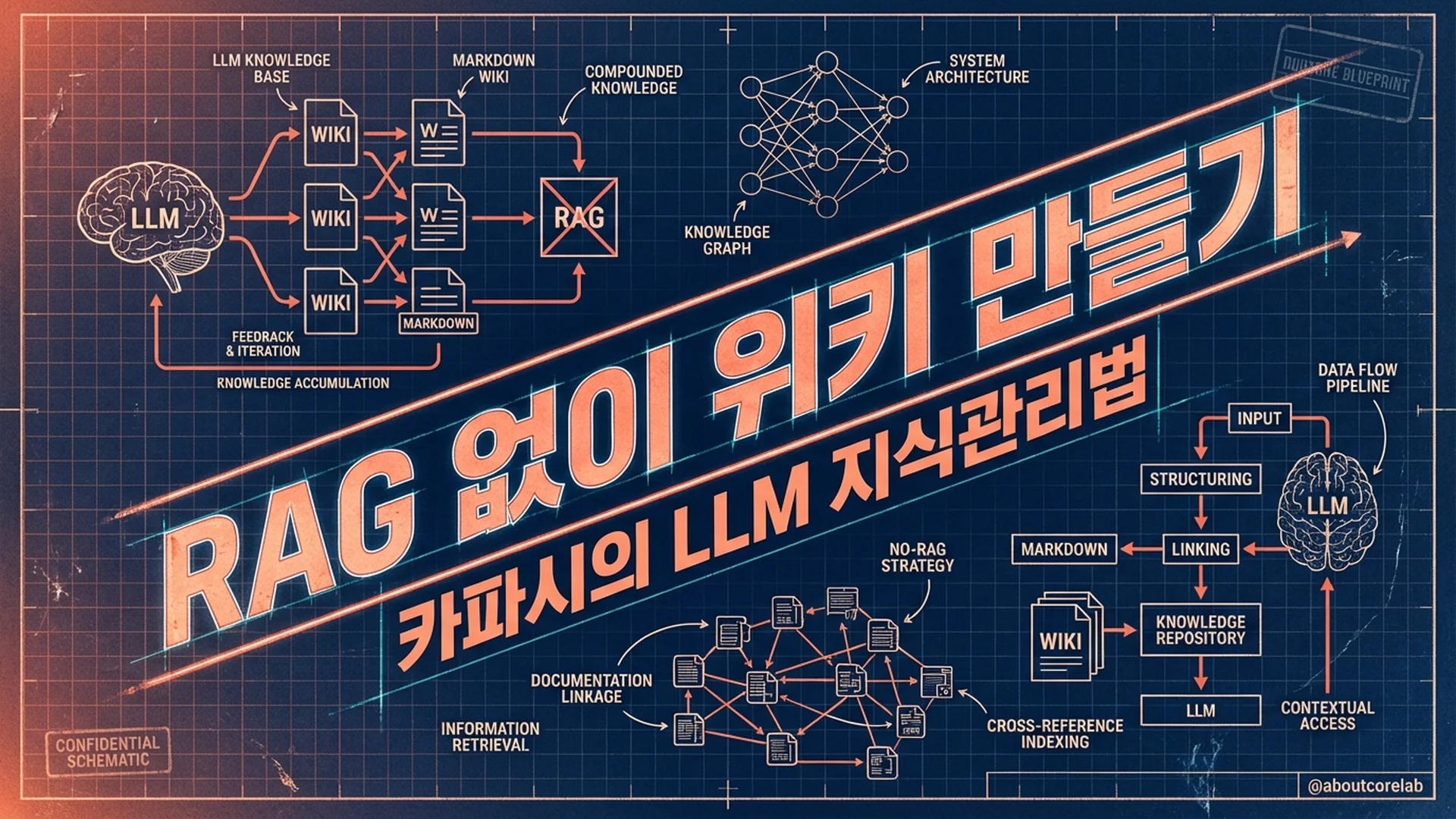
- 카파시는 RAG 파이프라인 없이 LLM이 마크다운 위키를 직접 구축/유지하는 ‘LLM Knowledge Base’ 시스템을 공개했다
- 약 100개 문서, 40만 단어 규모의 위키를 운영 중이며, 유지보수 비용이 사실상 0에 수렴한다
- 핵심은 도구가 아니라 13년간 일관된 원칙 — 능동적 참여, 구조화, 연결 — 위에 LLM을 얹은 것이다
코드에서 지식으로, 패러다임이 바뀌었다
카파시의 최근 행보는 ‘코드 조작에서 지식 조작으로’의 전환을 보여준다. 2025년 그가 만든 ‘vibe coding’이라는 단어는 AI 코딩의 대명사가 됐다. 그런데 불과 1년 만에 본인이 그걸 “이제 구식”이라고 선언했다. vibe coding에서 agentic engineering으로, 다시 LLM Knowledge Base로. 변화 속도가 빠르다.

출처: Vibe coding is passe. Karpathy has a new name for the future of software.
그가 GitHub Gist에 공개한 시스템의 골자는 단순하다. LLM에게 논문, 기사, 데이터셋 같은 원본 자료를 넘기면, LLM이 알아서 마크다운 위키를 만들고 유지한다. 벡터 데이터베이스도 없고, 복잡한 RAG 파이프라인도 없다. 마크다운 파일과 폴더 구조, 그리고 사서 역할을 하는 LLM이 전부다.

llm-wiki. GitHub Gist: instantly share code, notes, and snippets.
출처: llm-wiki
솔직히 처음 봤을 때 “이게 된다고?” 싶었다. 그런데 카파시 본인이 100개 문서, 40만 단어 규모에서 실제로 쓰고 있다고 하니 무시하기 어렵다.
3-Layer 아키텍처: 생각보다 단순하다
이 시스템은 세 개 레이어로 돌아간다.
| 레이어 | 역할 | 누가 관리하나 |
|---|---|---|
| Raw Sources | 논문, 기사, 이미지 등 원본 자료. 불변(immutable) | 인간이 수집 |
| Wiki | 마크다운 파일들 — 요약, 개념 정리, 백링크 | LLM이 전담 |
| Schema | 위키 구조와 규칙 정의 (CLAUDE.md 등) | 인간+LLM 공동 |
워크플로우도 세 단계다. 원본 자료를 raw/ 폴더에 넣는다(Data Ingest). LLM이 이걸 읽고 위키를 ‘컴파일’한다(LLM Compilation). 그리고 LLM이 주기적으로 위키 전체를 점검하며 불일치를 고치고 새 연결을 찾는다(Active Maintenance).
여기서 핵심은 ‘컴파일’이라는 단어 선택이다. 단순 요약이 아니다. 하나의 소스가 보통 10-15개 위키 페이지에 영향을 미친다. 새 논문 하나를 넣으면 기존 개념 페이지들이 업데이트되고, 관련 항목 간 백링크가 생기고, index.md가 갱신된다. 마치 컴파일러가 소스 코드를 바이너리로 변환하듯, LLM이 원시 정보를 구조화된 지식으로 변환하는 것이다.
그런데 RAG 없이 어떻게 원하는 정보를 찾을까. 카파시에 따르면, index.md(모든 페이지의 한 줄 요약)와 각 문서의 요약만으로 LLM이 충분히 네비게이션할 수 있다고 한다. “복잡한 RAG 파이프라인이 필요할 줄 알았는데, 이 규모에서는 그냥 된다”는 게 그의 설명이다.
물론 이건 100개 문서 규모의 이야기다. 수천, 수만 문서가 되면 다를 수 있다. 이 부분은 뒤에서 다시 짚겠다.
13년의 원칙이 LLM을 만나기까지
카파시의 지식관리법이 흥미로운 건 갑자기 나온 게 아니라는 점이다. 2013년 스탠포드 시절부터 이어진 원칙이 도구만 바꿔가며 진화해왔다.
2013년, 그는 학생들에게 이렇게 조언했다. “밤샘은 가치가 없다. 밤에 1시간 고민한 문제를 아침에 5분 만에 풀 수 있다.” 그리고 가장 강조한 건 ‘읽고 이해하는 것’과 ‘재현할 수 있는 것’은 완전히 다르다는 구분이었다. 책을 덮고 핵심을 직접 써내려갈 수 있어야 진짜 아는 것이다.
2020년에는 X에서 ‘전문가 되는 3단계’를 공유했다. (1) 구체적 프로젝트를 반복하며 깊이 학습한다 (2) 배운 걸 자기 말로 가르치거나 요약한다 (3) 과거의 자기 자신과만 비교한다. 이 공식은 그의 ‘Zero to Hero’ 유튜브 시리즈에 그대로 반영돼 있다.
2024년에는 학습의 ‘단편화(shortification)’를 강하게 비판했다. “10분 만에 배우기” 탭을 닫고 교과서를 펼쳐라. 4시간 블록을 잡고 노트 작성, 재독, 재구성을 하라. 콘텐츠를 열기 전에 “나는 지금 오락을 원하는가, 학습을 원하는가”를 먼저 결정하라.
그리고 2025년, 이 원칙들이 LLM과 결합했다. 카파시는 모든 글을 LLM과 함께 읽는 습관이 생겼다고 밝혔다. 3단계 읽기법이다. Pass 1에서 직접 읽고, Pass 2에서 LLM에게 설명/요약을 요청하고, Pass 3에서 Q&A를 진행한다. 중요한 건 반드시 수동 읽기가 먼저라는 것이다. LLM은 수동적 소비가 아니라 능동적 학습의 도구여야 한다.
결국 도구는 펜에서 LLM으로 바뀌었지만, ‘능동적 참여 + 구조화 + 연결’이라는 원칙은 13년간 한 번도 바뀌지 않았다. 2026년의 LLM Knowledge Base는 이 원칙의 최신 구현체일 뿐이다.
“인간은 위키를 포기한다” — 그래서 LLM이 한다
개인 위키나 세컨드 브레인을 시작했다가 포기한 경험이 있다면, 카파시의 다음 문장에 공감할 것이다. “인간이 전통적 위키를 포기하는 이유는 유지보수 부담이 인지된 가치를 초과하기 때문이다.”
Obsidian 사용자가 전 세계 150만 명을 넘었고, 커뮤니티 플러그인이 2,700개 이상이다. 그런데 정작 위키를 꾸준히 유지하는 사람은 소수다. 노트를 쌓기만 하고 연결하지 못하는 ‘디지털 쓰레기 문제’는 PKM(Personal Knowledge Management) 커뮤니티의 오래된 고민이다.
카파시의 해법은 명쾌하다. LLM은 피로를 느끼지 않는다. 크로스 레퍼런스 업데이트를 잊지 않는다. 한 번의 작업으로 15개 파일을 동시에 수정할 수 있다. 유지보수 비용이 0에 수렴하면, 위키의 가치가 항상 비용을 초과한다. 그래서 포기하지 않게 된다.
VentureBeat에 따르면, 이 접근법은 1945년 바네바 부시(Vannevar Bush)가 ‘As We May Think’에서 구상한 Memex — 개인적으로 큐레이션되고 문서 간 연결이 문서 자체만큼 가치 있는 지식 저장소 — 의 실현이다. 부시가 80년 전에 상상만 했던 것을 LLM이 유지보수 문제를 해결함으로써 현실로 만든 셈이다.

Karpathy proposes something simpler and more loosely, messily elegant than the typical enterprise solution of a vector database and RAG pipeline.
출처: Karpathy shares ‘LLM Knowledge Base’ architecture that bypasses RAG with an evolving markdown library maintained by AI
실무에 적용할 때 주의할 점
카파시의 포스트 이후 커뮤니티에서 다양한 구현 사례가 나왔다. 그중에서 반복적으로 등장하는 실무 교훈이 있다.
분류가 먼저다. 50페이지짜리 보고서와 2페이지짜리 메모는 다른 처리가 필요하다. 문서 유형에 따라 추출 전략을 달리하면 토큰도 아끼고 결과도 좋아진다.
토큰 예산을 잡아야 한다. 컨텍스트 윈도우가 100만 토큰을 넘어선 시대지만, 무한하진 않다. L0(프로젝트 컨텍스트, ~200 토큰)부터 L3(전체 문서, 5-20K 토큰)까지 단계별로 예산을 명시하면 오버플로우를 막을 수 있다.
이중 출력 규칙을 지켜야 한다. 모든 작업은 직접적 산출물 + 위키 업데이트, 두 가지를 생산해야 한다. 이 규칙이 없으면 지식이 채팅 히스토리 속으로 증발한다.
그리고 가장 중요한 경고가 있다. LLM이 출처 없이 정보를 합성할 수 있다는 것이다. 커뮤니티에서 반복적으로 지적되는 문제다. 출처 인용을 강제하고, 정기적으로 스팟체크를 하고, 인간이 ‘편집장(editor-in-chief)’ 역할을 유지하지 않으면 위키의 신뢰성이 급격히 떨어진다.
스케일링 한계도 솔직히 인정해야 한다. 100개 문서에서 잘 돌아가는 것과 1만 개 문서에서 잘 돌아가는 것은 다른 이야기다. 대규모에서는 여전히 임베딩 기반 검색이 필요할 수 있고, 소규모 LLM Wiki + 대규모 RAG의 하이브리드 전략이 현실적인 답일 수 있다.
인사이트
첫 번째로는, 카파시의 방법론에서 진짜 배울 것은 도구가 아니라 원칙이다. Obsidian이든 Notion이든 상관없다. ‘능동적 참여 + 구조화 + 연결’이 빠지면 어떤 도구를 써도 디지털 쓰레기통이 된다. LLM은 이 원칙의 실행 비용을 극적으로 낮춰준 것이지, 원칙 자체를 대체한 게 아니다.
두 번째는, 지식관리의 경쟁 우위가 ‘수집량’에서 ‘구조화 속도’로 이동하고 있다는 것이다. 정보는 누구나 접근할 수 있다. 차이를 만드는 건 그 정보를 얼마나 빠르게 구조화하고, 연결하고, 활용 가능한 형태로 만드느냐다. LLM Knowledge Base는 이 구조화 속도를 비약적으로 높인다. 카파시 표현대로라면, 지식이 ‘복리로 축적’되기 시작하는 것이다.
마무리
당장 시도해볼 수 있는 한 가지가 있다. 지금 관심 있는 주제 하나를 골라서, 관련 자료 5-10개를 모으고, LLM에게 “이 자료들로 위키를 만들어줘”라고 요청해보는 것이다. index.md를 만들고, 개념별 페이지를 생성하고, 백링크를 연결하게 한다. 완벽할 필요 없다. 카파시도 처음부터 100개 문서 위키를 만든 게 아니다.
다만 하나만 기억하자. LLM에게 맡기되, 편집장은 내가 해야 한다.
참고 자료
- Andrej Karpathy, “LLM Knowledge Bases” (GitHub Gist)
- VentureBeat, “Karpathy shares LLM Knowledge Base architecture that bypasses RAG”
- The New Stack, “Vibe coding is passe”
- Antigravity Codes, “Karpathy’s LLM Knowledge Bases: The Post-Code AI Workflow”
- HowAIWorks.ai, “Building Personal Knowledge Bases with LLMs: The Karpathy Method”


