AI 모델을 선택할 때 가장 먼저 드는 고민은 아마도 “성능이 좋은 모델은 너무 비싸고, 저렴한 모델은 성능이 아쉽다”는 딜레마일 것이다. 그런데 만약 최상위 모델의 성능을 1/5 가격에 쓸 수 있다면 어떨까. Anthropic이 2026년 2월 17일 출시한 Claude Sonnet 4.6은 바로 이 질문에 대한 답을 내놓았다. 오피스 업무, 재무 분석, 수학 추론에서 자사 플래그십 모델인 Opus 4.6을 넘어서면서도 가격은 동일하게 유지한 것이다.
이 글에서는 Sonnet 4.6이 무엇이 달라졌는지, 왜 주목해야 하는지, 그리고 실무에서 어떻게 활용할 수 있는지를 살펴보고자 한다.
Sonnet 4.6은 어떤 모델인가
Claude Sonnet 4.6은 Anthropic의 모델 라인업에서 중간 티어에 해당하는 모델이다. 입력 3달러, 출력 15달러(백만 토큰 기준)로 이전 버전인 Sonnet 4.5와 동일한 가격을 유지했다. 플래그십 모델인 Opus 4.6이 입력 15달러, 출력 75달러인 것을 고려하면 정확히 1/5 수준이다.
그런데 단순히 저렴하기만 한 것이 아니다. Anthropic에 따르면 Claude Code 초기 테스트에서 개발자의 70%가 이전 버전인 Sonnet 4.5보다 4.6을 선호했고, 심지어 이전 세대의 플래그십 모델인 Opus 4.5와 비교해서도 59%의 사용자가 Sonnet 4.6을 선택했다고 한다. 사용자들은 과도한 엔지니어링이 줄었고 지시 이행 능력이 뛰어나다고 평가했다.
현재 claude.ai의 무료 및 Pro 플랜 기본 모델로 설정되어 있으며, Amazon Bedrock, Azure AI Foundry, Google Vertex AI에서도 동시에 사용할 수 있다.
숫자로 보는 성능, 정말 Opus를 넘어섰나
벤치마크 수치만 놓고 보면 Sonnet 4.6의 성능은 상당히 인상적이다.
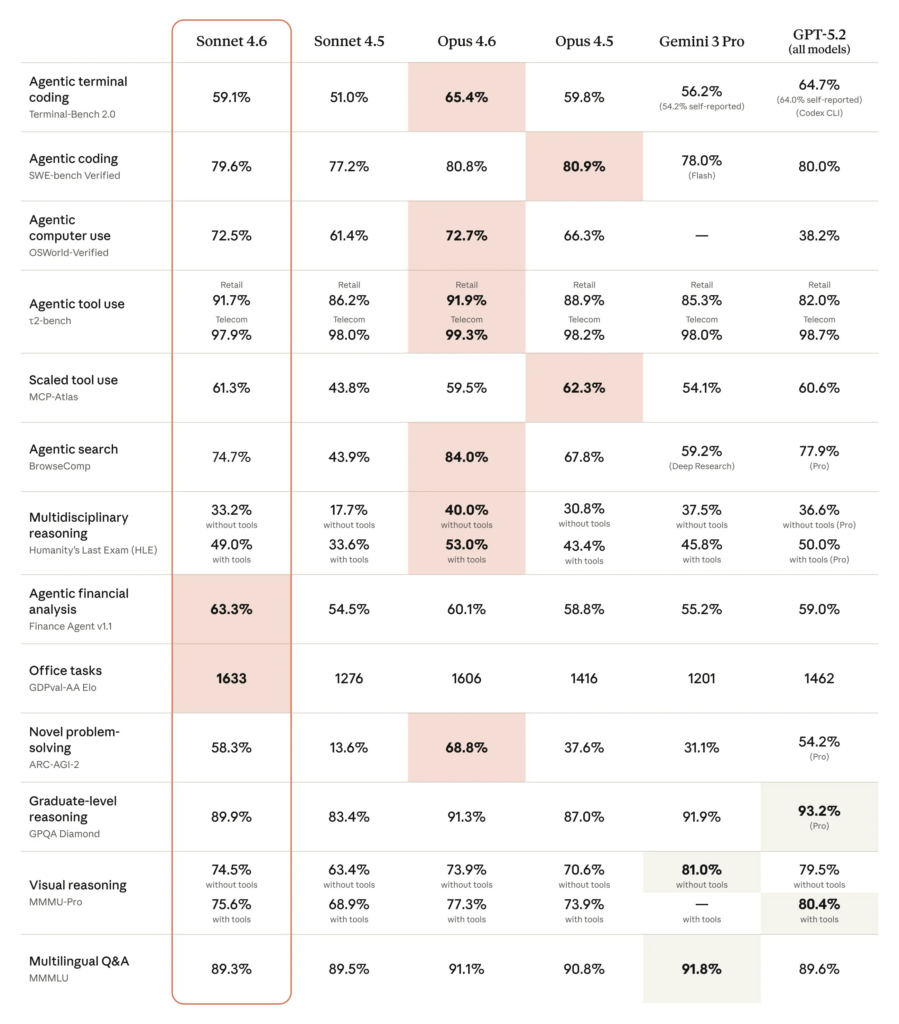
코딩 능력을 측정하는 SWE-bench Verified에서 79.6%를 기록했다. Opus 4.6의 80.8%와 불과 1.2%p 차이로, Sonnet과 Opus 간의 성능 격차가 역대 가장 좁아졌다. 실제 GitHub 이슈를 해결하는 능력을 측정하는 벤치마크인 만큼, 이 수치는 실무 코딩 능력을 반영한다고 볼 수 있다.
더 주목할 만한 것은 일부 영역에서 Opus를 아예 넘어선 점이다. 오피스 업무 평가인 GDPval-AA에서 1633 Elo를 기록해 Opus 4.6보다 27 Elo 포인트 높은 전체 1위를 달성했다. 재무 분석 벤치마크인 Finance Agent v1.1에서도 63.3%로 Opus 4.6의 60.1%를 앞섰다.
물론 모든 영역에서 Opus를 넘어선 것은 아니다. 과학 추론을 측정하는 GPQA Diamond에서는 74.1%로 Opus 4.6의 91.3%에 17%p 이상 뒤처진다. 심층적인 과학 추론이나 고위험 전문 분야에서는 여전히 플래그십 모델이 필요한 것으로 보인다.
컴퓨터 사용 72.5%, 이 숫자가 왜 중요한가
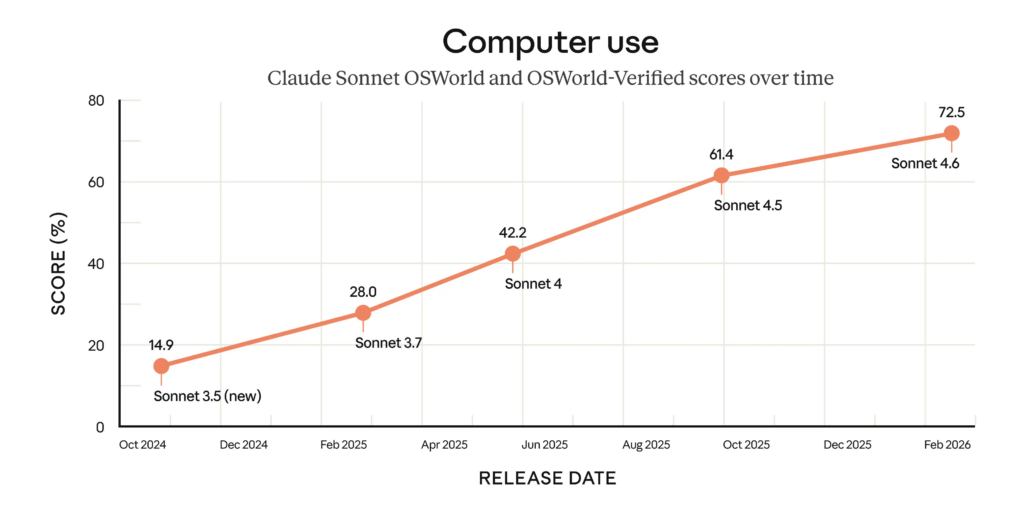
Sonnet 4.6의 가장 강력한 차별화 포인트는 컴퓨터 사용 능력이다. OSWorld-Verified 벤치마크에서 72.5%를 기록했는데, 이것이 왜 의미 있는지 맥락을 살펴볼 필요가 있다.
이 벤치마크는 AI가 실제 화면을 보고 Chrome, LibreOffice, VS Code 같은 소프트웨어를 사람처럼 직접 조작하는 능력을 측정한다. 2024년 10월 이 기능이 처음 도입되었을 때 성능은 14.9%에 불과했다. 16개월 만에 약 5배 향상된 것이다.
경쟁사와 비교하면 격차가 더 명확해진다. OpenAI의 GPT-5.2가 같은 벤치마크에서 38.2%를 기록한 것과 비교하면 34.3%p 차이로, 에이전트 AI 컴퓨터 사용 분야에서 독보적인 1위라 할 수 있다.
이것이 실무에서 의미하는 바는 무엇일까. API가 없는 레거시 소프트웨어, 예를 들어 보험 포털이나 정부 데이터베이스, 오래된 ERP 시스템 같은 것들을 AI가 화면을 보고 직접 조작해서 자동화할 수 있다는 뜻이다. 별도의 커넥터나 통합 개발 없이도 기존 소프트웨어를 자동화하는 것이 가능해지는 것이다. 실제로 보험 워크플로우에서 94% 정확도를 달성한 사례가 보고되었다.
가트너는 2026년까지 기업 애플리케이션의 40%가 작업 특화 AI 에이전트를 탑재할 것으로 전망하고 있다. Sonnet 4.6의 컴퓨터 사용 능력은 이 전망을 현실로 만드는 핵심 기술 중 하나로 보인다.
주목해야 할 4가지 핵심 기능
100만 토큰 컨텍스트 윈도우
Sonnet 계열 최초로 100만 토큰 컨텍스트 윈도우를 베타로 지원한다. 약 75만 단어, 2,500페이지 분량의 텍스트를 단일 세션에서 처리할 수 있다. GPT-4o의 128K 토큰과 비교하면 약 8배에 달하는 수준이다.
실무적으로는 전체 코드베이스를 한 번에 로드해서 분석하거나, 수십 개의 연구 논문을 한 세션에서 검토하는 것이 가능해진다.
적응형 사고
작업의 복잡도에 따라 추론 깊이를 동적으로 결정하는 기능이다. 단순한 질문에는 빠르게, 복잡한 문제에는 더 깊이 사고하여 비용과 성능을 동시에 최적화한다.
컨텍스트 압축
장기 대화에서 컨텍스트 한도에 가까워질 때 이전 대화의 핵심 내용을 자동으로 압축하는 기능이다. 단순 삭제가 아니라 핵심 정보를 보존하면서 압축하기 때문에, 사실상 무한한 대화를 이어갈 수 있다.
에이전트 기능 GA 전환
코드 실행, 메모리, 도구 호출이 정식 출시 상태로 전환되었다. 에이전트 애플리케이션을 구축하는 진입 장벽이 크게 낮아진 셈이다.
그러면 Opus는 언제 써야 하나
Sonnet 4.6이 이렇게 뛰어나다면 Opus 4.6은 언제 필요한 것일까. 결론부터 말하면, 대부분의 업무에서는 Sonnet 4.6으로 충분하다.
하지만 심층 과학 추론이 필요한 경우(GPQA Diamond 91.3% vs 74.1%), 의료나 법률처럼 높은 정확도가 요구되는 고위험 분야, 복잡한 멀티에이전트 시스템을 조율해야 하는 경우에는 여전히 Opus가 더 적합한 것으로 보인다.
일반 개발, 오피스 업무, 재무 분석, 에이전트 앱 개발, 비용에 민감한 프로젝트라면 Sonnet 4.6이 합리적인 선택이 될 것이다.
인사이트
첫 번째로는 중간 티어 모델이 플래그십을 넘어서는 현상에 주목할 필요가 있다. Sonnet 4.6이 오피스 업무와 재무 분석에서 Opus를 앞선 것은 AI 성능 민주화의 가속을 의미한다. 앞으로 플래그십 모델과 중간 티어 모델의 격차는 특정 전문 분야로만 좁혀질 것으로 보이며, 이는 기업의 AI 도입 비용을 크게 낮출 수 있는 긍정적인 신호다.
두 번째는 컴퓨터 사용 능력이 에이전트 AI 시대의 핵심 경쟁력이 되고 있다는 점이다. OSWorld 72.5%라는 수치는 AI가 실제 소프트웨어를 사람처럼 조작하는 능력이 실용적 수준에 도달했음을 보여준다. 특히 레거시 시스템 자동화는 많은 기업이 디지털 전환에서 겪는 가장 큰 병목이었는데, 이 문제에 대한 새로운 해법이 열린 것으로 이해할 수 있다.
세 번째로는 AI 모델 선택의 기준이 바뀌고 있다는 것이다. 과거에는 “가장 좋은 모델”을 쓰는 것이 당연했지만, Sonnet 4.6은 “작업에 맞는 모델”을 쓰는 것이 더 현명한 전략임을 보여준다. 오피스 업무에 Opus를 쓰는 것은 오히려 비효율적일 수 있다. 용도에 따라 모델을 유연하게 선택하는 접근이 앞으로 더욱 중요해질 것으로 생각된다.
마무리
Claude Sonnet 4.6은 “비싼 모델이 곧 좋은 모델”이라는 공식을 깨뜨리고 있다. 대부분의 실무 영역에서 플래그십 수준의 성능을 1/5 가격에 제공하며, 특히 컴퓨터 사용 분야에서의 독보적인 성능은 에이전트 AI 시대를 현실로 만들어가고 있다.
물론 모든 영역에서 Opus를 대체할 수 있는 것은 아니다. 심층 과학 추론이나 고위험 전문 분야에서는 여전히 플래그십 모델이 필요하다. 하지만 일반 개발, 오피스 업무, 에이전트 앱 구축을 고려하고 있다면 Sonnet 4.6은 현재 가장 합리적인 선택지 중 하나일 것이다.
AI 모델 선택에서 중요한 것은 가격표가 아니라 자신의 용도에 맞는 모델을 고르는 눈이다. Sonnet 4.6이 보여주는 것처럼, 때로는 중간 티어가 최상의 선택이 될 수 있다.