
새 AI 모델이 나오면 보통 두 가지를 본다. 얼마나 똑똑해졌나, 그리고 얼마나 비싸졌나. 그런데 5월 28일 Anthropic이 내놓은 Claude Opus 4.8은 앞쪽만 올리고 뒤쪽은 건드리지 않았다. 성능은 한 단계 올라갔는데 쓰는 값은 4.7 때랑 똑같다. AI를 일로 쓰는 사람한테는 이게 꽤 반가운 조합이다.
핵심 요약
Opus 4.8은 코딩·에이전트 성능을 끌어올리면서 정규 가격을 그대로 묶었다. 같은 돈으로 더 나은 결과가 나오는 셈이다. 빠른 모드 값은 오히려 3분의 1로 떨어졌고, Anthropic은 같은 날 회사 가치가 OpenAI를 넘었다는 소식까지 함께 발표했다.
가격이 안 올랐다는 게 왜 큰일인가
이번 발표에서 제일 먼저 눈에 띄는 건 가격이다. AI 모델은 보통 새 버전이 나올수록 비싸지는 게 당연했는데, Opus 4.8은 그 공식을 깼다.

(Claude Opus 4.8 제품 소개, 출처: https://www.anthropic.com/claude/opus)
정규 사용 기준으로 입력 100만 토큰에 $5, 출력 100만 토큰에 $25다. 직전 모델인 4.7과 똑같다. 토큰(token)은 AI가 글을 잘게 쪼개 처리하는 단위인데, 한국어로는 대략 한 글자가 한 토큰 안팎이라고 보면 감이 온다. 쉽게 말하면 AI한테 일을 시키는 단가가 그대로인데 일은 더 잘하게 됐다는 뜻이다.
더 흥미로운 건 빠른 모드(fast mode)다. 답을 약 2.5배 빠르게 뱉어내는 모드인데, 4.7에서는 출력 100만 토큰에 $150이었던 게 4.8에서는 $50으로 내려갔다. 3분의 1 토막이다. 실시간으로 답이 튀어나와야 하는 챗봇이나, 한 번에 글을 대량으로 찍어내는 작업에서는 이 차이가 곧장 비용으로 느껴진다.
이게 왜 일이냐면, 그동안 “AI 도입을 미룬 이유” 중 큰 하나가 “비싸서”였기 때문이다. 그 핑계가 이번에 사라졌다. 새 버전으로 갈아타도 청구서가 안 늘어나니까, 한번 써볼지 말지 고민하던 사람한테는 망설일 이유가 한 개 줄어든 셈이다.
코딩과 에이전트에서 격차를 벌렸다
성능 얘기를 하면 숫자가 많아지는데, 핵심만 보면 코딩과 에이전트 쪽에서 Opus 4.8이 한 발 앞섰다.
코딩 실력을 재는 대표 시험이 SWE-bench다. 실제 GitHub에 올라온 버그 리포트를 주고 “이거 고쳐봐”라고 시키는 식이다. 그중 어려운 버전인 SWE-bench Pro에서 Opus 4.8은 69.2%를 풀었다. 직전 4.7은 64.3%, 경쟁 모델 GPT-5.5는 58.6%였다.
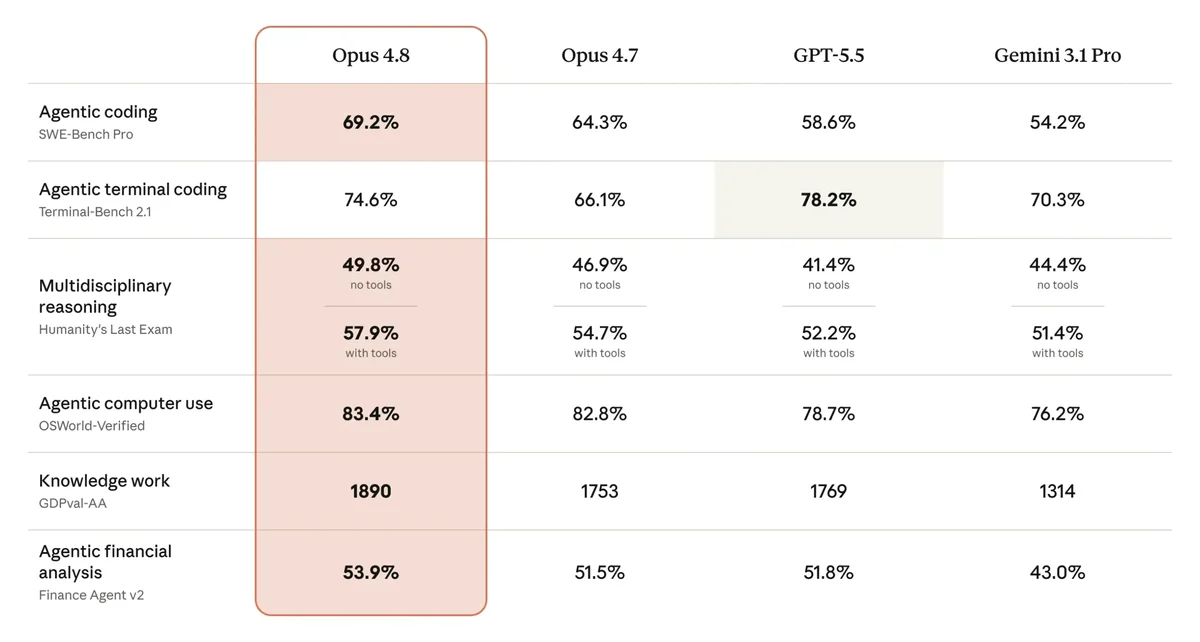
(Opus 4.8과 Opus 4.7·GPT-5.5·Gemini 3.1 Pro 벤치마크 비교, 출처: https://the-decoder.com/anthropic-ships-claude-opus-4-8-as-a-modest-but-tangible-improvement-that-tops-gpt-5-5-in-most-benchmarks/)
SWE-bench Pro · 어려운 코딩 문제 해결률
- Claude Opus 4.8 ▓▓▓▓▓▓▓░░░ 69.2%
- Claude Opus 4.7 ▓▓▓▓▓▓░░░░ 64.3%
- GPT-5.5 ▓▓▓▓▓▓░░░░ 58.6%
한 칸 = 10%p
여기서 에이전트(agentic AI)라는 말이 자주 나오는데, 이건 AI가 사람이 일일이 시키지 않아도 도구를 스스로 골라 쓰며 여러 단계를 알아서 처리하는 걸 말한다. 검색하고, 파일 열고, 코드 고치고, 다시 확인하는 과정을 혼자 쭉 밀고 나가는 식이다. Opus 4.8은 이런 다단계 작업을 끝까지 완주하는 테스트에서 모든 케이스를 완료한 유일한 모델로 기록됐다. 100만 토큰짜리 긴 문서에서 필요한 걸 찾아내는 능력도 40.3%에서 68.1%로 크게 올랐다.
물론 다 이긴 건 아니다. 터미널에서 명령어를 직접 다루는 시험인 Terminal-Bench 2.1에서는 GPT-5.5가 78.2%로 Opus 4.8(74.6%)을 앞섰다. 모든 일에 한 모델이 정답은 아니라는 얘기다. 글쓰기랑 코드 정리는 이 모델, 터미널 작업은 저 모델, 이런 식으로 골라 쓰는 시대가 됐다.
“가장 정직한 모델”이라는 색다른 자랑
이번에 Anthropic이 유난히 강조한 건 속도나 점수가 아니라 정직함이었다. Opus 4.8을 “가장 정직한 모델”로 내세웠다.
무슨 말이냐면, AI가 모르면서 아는 척하거나, 틀린 코드를 슬쩍 통과시키거나, 중요한 걸 사용자한테 안 알리고 넘어가는 행동을 줄였다는 거다. 실제로 결함 있는 코드를 그냥 넘기는 비율이 4.7 대비 약 4분의 1로 줄었고, 중요한 사건을 사용자에게 안 알리는 비율은 3.7%까지 떨어졌다. 근거 없이 자신만만하게 답하는 버릇도 10배 넘게 줄었다고 한다.
회사는 이 결과를 244쪽짜리 안전 평가 문서로 공개했다. 숫자만 던지는 게 아니라 근거 문서까지 같이 내놨다는 점에서 자신감이 묻어난다.
이게 생각보다 중요하다. AI한테 일을 맡길 때 제일 무서운 건 틀린 답이 아니라, 틀렸는데 맞은 척하는 답이다. 그럴듯하게 써놨는데 알고 보니 거짓이면 검증하느라 더 고생한다. 검색 엔진이 처음 나왔을 때 “정보는 많은데 뭘 믿어야 하나”가 숙제였던 것처럼, 지금 AI도 “똑똑한 건 알겠는데 믿어도 되나”가 관건이다. 정직함을 전면에 내세운 건 그 지점을 정확히 노린 포지셔닝이다.
사용자가 직접 조절할 수 있는 기능도 늘었다. AI가 한 문제에 들이는 고민의 양을 Low부터 Max까지 직접 고를 수 있다. 가벼운 질문엔 빠르게, 복잡한 작업엔 깊게 생각하라고 시키는 식이다.
같은 날 회사 몸값이 OpenAI를 넘었다
모델 발표와 함께 회사 소식도 하나 터졌다. Anthropic이 65조 원 규모(약 $65B)를 새로 투자받으면서 회사 가치가 약 965조 원(약 $965B)으로 평가됐다. 이걸로 경쟁사 OpenAI(약 850조 원)를 처음으로 넘어섰다.

(Anthropic $65B 조달·$965B 밸류에이션, 출처: https://techcrunch.com/2026/05/28/anthropic-raises-65-billion-nears-1t-valuation-ahead-of-ipo/)
숫자가 너무 커서 와닿지 않는데, 한 가지만 보면 된다. Anthropic의 연 환산 매출이 올해 초 9조 원대에서 5월에 47조 원대로 뛰었다. 그것도 매출의 80%가 기업 고객에서 나온다. Netflix, Spotify 같은 회사들이 Claude로 코드를 짜고 있다는 얘기다. 개인이 심심풀이로 쓰는 장난감이 아니라 회사들이 돈 내고 일에 쓰는 도구로 자리를 잡았다는 신호다.
이 흐름은 우리가 어떤 AI를 고를지에도 영향을 준다. 모델 셋이 이제 서로 다른 자리를 차지하기 시작했다. 값싸게 대량으로 돌리거나 영상·이미지를 다루는 일은 Google의 Gemini가, 두루두루 무난한 범용 작업은 GPT-5.5가, 코딩과 믿고 맡기는 에이전트 작업은 Claude가 가져가는 모양새다. 하나만 잘 고르면 끝나던 시절은 지났고, 일에 따라 골라 쓰는 게 자연스러워졌다.
정리
이번 발표의 핵심은 셋이다. 가격은 그대로인데 코딩·에이전트 성능이 올랐다. 빠른 모드 값은 3분의 1로 떨어졌다. 정직함을 새 차별점으로 내세웠다.
세 가지가 같은 날 같이 움직였다는 게 진짜 의미다. 그동안 AI 도입을 미루는 이유는 대개 “아직 비싸서” 아니면 “아직 못 믿어서”였는데, 이번에 둘 다 약해졌다. 같은 돈으로 더 정확하고 더 믿을 만한 결과가 나오니까, 이제 질문이 “AI가 이 일을 할 만큼 똑똑한가”에서 “내 일 중 어디부터 맡겨볼까”로 바뀐다. 기존에 Claude를 쓰던 사람이라면 갈아타는 부담이 거의 없으니 코딩이나 반복 작업부터 한번 붙여보고, 터미널 작업처럼 GPT-5.5가 앞서는 영역은 비교해본 뒤 정하면 된다.
참고 자료
- Anthropic, Introducing Claude Opus 4.8 (2026-05-28)
- Anthropic, Claude Opus 제품 페이지 (2026-05-28)
- VentureBeat, Opus 4.8 3배 싼 빠른 모드 (2026-05-28)
- The Decoder, GPT-5.5 대비 벤치마크 (2026-05-28)
- Inc., “가장 정직한 모델” (2026-05-28)
- Bloomberg, $965B 밸류에이션 OpenAI 추월 (2026-05-28)
- TechCrunch, $65B 조달·IPO 준비 (2026-05-28)


