Andrej Karpathy가 4월 초 GitHub Gist에 올린 LLM Wiki 패턴을 보고 한 대 맞은 느낌이었다. Obsidian과 Claude Code 조합으로 세컨드 브레인을 만들고 있던 참이었는데, 퍼즐의 빠진 조각을 찾은 것 같았다.

llm-wiki. GitHub Gist: instantly share code, notes, and snippets.
출처: llm-wiki
기존에도 Obsidian + Claude Code로 지식 그래프를 만들어본 적이 있다. 그런데 LLM Wiki 방식으로 다시 해보니 차이가 분명했다. 원본 소스에서 엔티티와 컨셉을 체계적으로 추출하는 과정이 있기 때문에, 지식의 구조화 수준이 다른 차원이었다.
RAG가 놓치는 것
지식 관리에서 RAG의 근본적인 문제는 축적이 없다는 점이다. PDF 10개를 올려놓고 질문하면, LLM은 매번 벡터 검색으로 관련 청크를 찾아서 조합한다. 내일 같은 질문을 해도 똑같은 작업을 처음부터 반복한다. 5개 문서를 교차 분석해야 하는 질문이라면? 매번 흩어진 조각을 주워 맞추는 셈이다.
Karpathy는 이걸 “컴파일 타임 vs 쿼리 타임”이라는 프레임으로 설명한다. RAG는 쿼리 타임에 지식을 조립하고, LLM Wiki는 인제스트 타임에 한 번 정리해둔다. 합성 비용이 수집 시점에 한 번만 발생한다는 게 핵심이다.Atlan의 분석에 따르면, LLM Wiki는 소규모 지식 베이스에서 토큰 사용량을 최대 95%까지 줄일 수 있다.

출처: LLM Wiki vs RAG Knowledge Base – Atlan
Karpathy 본인의 위키가 이를 증명한다. 하나의 ML 연구 주제만으로 약 100개 문서, 40만 단어 분량의 위키가 만들어졌다. 박사 논문보다 긴 분량인데, Karpathy가 직접 쓴 문장은 하나도 없다.
그렇다면 실제로 어떻게 구성하면 될까.
세 개의 레이어, 그게 전부다
LLM Wiki의 구조는 놀라울 정도로 단순하다.
| 레이어 | 역할 | 내용 |
|---|---|---|
| Raw Sources | 원본 저장소 | PDF, 기사, 회의록 등 불변 소스 |
| The Wiki | 지식 페이지 | LLM이 작성/유지하는 마크다운 파일 |
| The Schema | 규칙 정의 | 위키 구조와 워크플로우를 정의하는 설정 |
raw 폴더에 원본을 넣으면 LLM이 읽고, 요약하고, 엔티티와 개념을 추출해서 위키 페이지로 만든다. 교차 참조도 자동으로 걸린다. Karpathy의 표현을 빌리면, “지식 베이스 유지의 지루한 부분은 읽기나 사고가 아니라 정리 작업” 이고, LLM이 바로 그 정리 작업을 맡는 것이다.
Claude Code로 커맨드 만들기
LLM Wiki 구축 과정은 예상보다 간단했다.
- Karpathy의 llm-wiki gist를 다운로드한다
- Claude Code에 해당 프롬프트를 참조해서 위키 구성을 요청한다
- 커맨드를 생성하고 활용한다
Claude Code의 sub agent와 skill 개념에 익숙했기 때문에, 이 구조를 기반으로 커맨드를 설계해달라고 요청했다. 그렇게 만들어진 핵심 커맨드 4개가 LLM Wiki의 전부다.
/ingest – 소스를 지식으로 변환
raw/ 폴더의 소스 문서를 분석하여 소스 요약 페이지를 생성하고, 관련 엔티티와 개념 페이지를 만들거나 업데이트한다. 인덱스, 개요, 로그까지 자동 갱신된다. 하나의 소스를 넣으면 여러 위키 페이지가 동시에 업데이트된다.
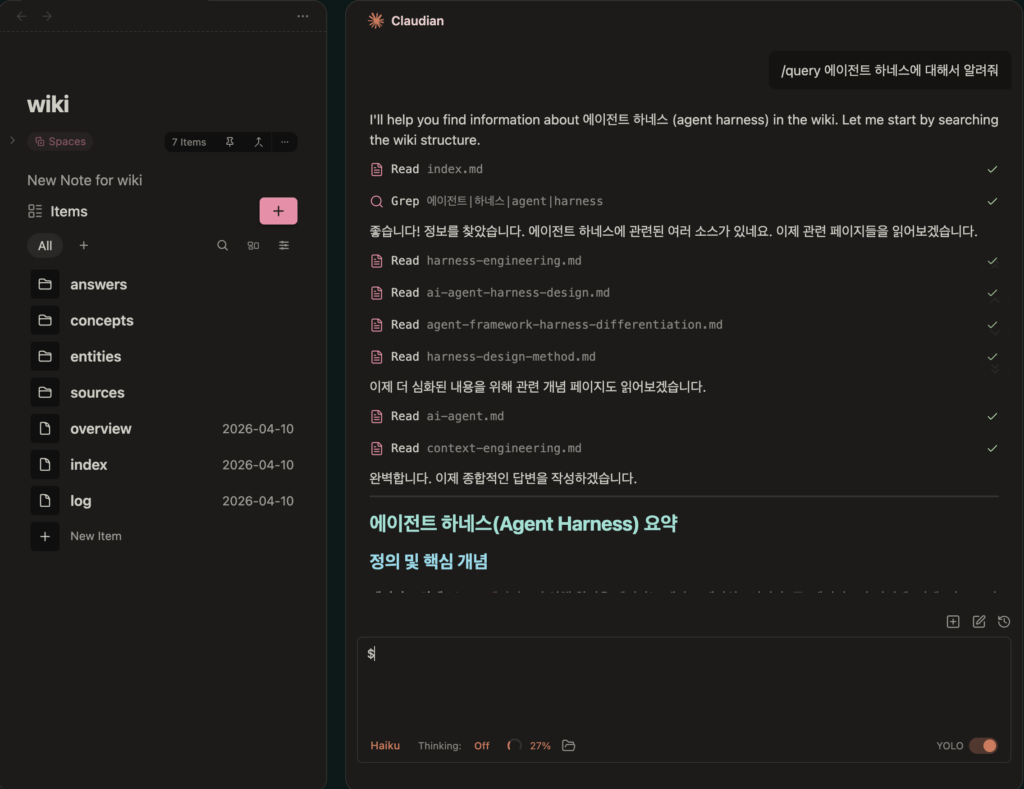
/query – 위키 전체를 검색하고 종합
위키 전체를 검색하여 관련 페이지를 읽고, 출처를 인용한 종합 답변을 합성한다. 단순한 키워드 매칭이 아니다. 이미 정리된 지식 위에서 추론하기 때문에 맥락을 잘 잡는다. 신뢰도 평가(높음/중간/낮음)도 포함된다.
/file-answer – 답변을 다시 지식으로
이 커맨드가 LLM Wiki의 가장 흥미로운 부분이다. /query의 결과를 wiki/answers/에 위키 페이지로 저장한다. 질문에 대한 답변이 다시 위키의 소스가 되는 구조다. 지식이 순환하면서 점점 확장되는데, 이 피드백 루프가 세컨드 브레인을 단순 저장소가 아닌 성장하는 지식 체계로 만든다.
/lint – 위키 건강 검진
고아 페이지, 깨진 링크, 프론트매터 오류, 소스 간 모순 등을 탐지하여 보고한다. 위키가 커질수록 이런 정비 작업이 중요해진다.
153개 리포트에서 지식 그래프가 만들어지기까지
Obsidian에 잠자고 있던 153개의 리서치, 센싱 리포트를 raw 폴더로 옮기고 /ingest를 전체적으로 돌렸다.
결과는 이랬다.
- 146개 소스 인제스트 완료
- 48개 엔티티 자동 추출 (기업, 인물, 기술 등)
- 29개 컨셉 자동 생성 (개념, 패턴, 프레임워크 등)
153개 파일 중 146개가 유효 소스로 처리된 건 나름 높은 비율이다. 그리고 숫자보다 중요한 건 이 페이지들이 서로 연결되어 있다는 점이다. 엔티티 페이지에서 관련 컨셉으로, 컨셉 페이지에서 원본 소스로 자연스럽게 이동할 수 있다. Obsidian의 그래프 뷰에서 보면 지식의 연결 구조가 한눈에 들어온다.
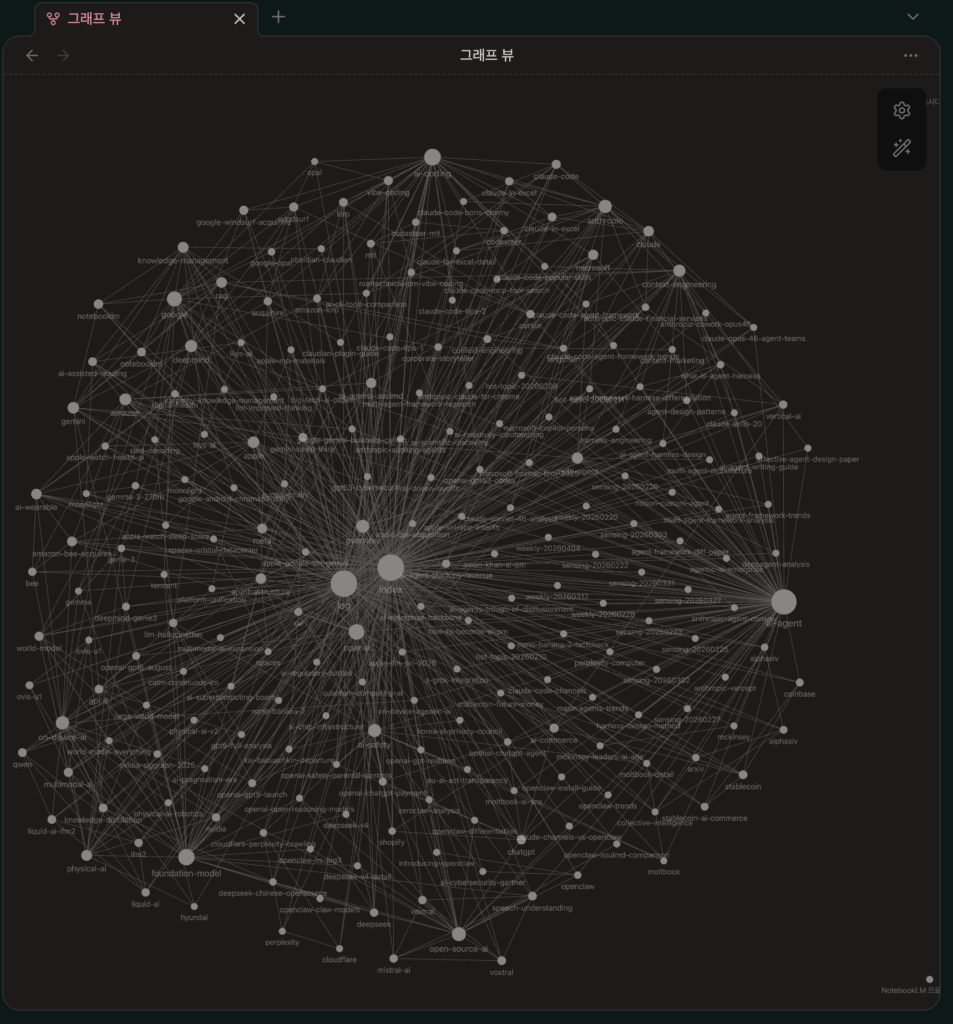
이전 방식과의 차이를 체감한 부분이 있다. 예전에는 노트를 직접 태깅하고 링크를 걸어야 했다. LLM Wiki는 소스의 내용을 이해하고 자동으로 분류 체계를 만든다. 정리 작업의 부담이 거의 사라진다. 48개의 엔티티와 29개의 컨셉을 수동으로 분류했다면 며칠은 걸렸을 작업이다.
그런데 이 구축한 위키를 어떻게 활용하느냐가 진짜 관건이다.
Obsidian + Claudian, 터미널 없이 위키 활용하기
한 가지 꿀팁이 있다. Claudian이라는 Obsidian 플러그인이다. Claude Code를 Obsidian 사이드바에 임베드해주는 플러그인인데, 이걸 쓰면 터미널을 열지 않고도 /query를 할 수 있다.
An Obsidian plugin that embeds Claude Code as an AI collaborator in your vault – YishenTu/claudian
출처: GitHub – YishenTu/claudian: An Obsidian plugin that embeds Claude Code as an AI collaborator in your vault
흐름이 이렇게 된다. Obsidian에서 그래프 뷰로 지식 구조를 탐색하다가, 궁금한 게 생기면 사이드바에서 바로 /query로 질문한다. 답변이 괜찮으면 /file-answer로 위키에 저장한다. 탐색 – 질문 – 지식화가 하나의 도구 안에서 끊김 없이 이뤄진다.
Claudian이 좋은 이유는 볼트 내 파일에 직접 접근할 수 있다는 점이다. 파일 읽기, 쓰기, 검색, bash 명령까지 전부 지원하기 때문에 LLM Wiki 커맨드가 그대로 동작한다. 별도 설정 없이 Claude Code CLI만 설치되어 있으면 바로 쓸 수 있다.
웹사이트로 빌드하기
구축한 LLM Wiki를 웹사이트로도 빌드해봤다. Obsidian에서 Claudian으로 운영하는 것도 편하지만, 가독성 면에서는 웹사이트가 더 낫다고 판단했다.
실제로 빌드해보니 상당히 만족스러웠다. 위키 특유의 페이지 간 링크 구조가 웹에서 훨씬 직관적으로 보인다. Obsidian은 편집과 운영에, 웹사이트는 열람과 공유에 각각 강점이 있다. 둘을 병행하는 게 현재로서는 가장 효과적인 조합이다.

아직 남은 과제
솔직히 아직 갈 길이 멀다. 사용하면서 느끼는 개선 포인트가 세 가지 있다.
할루시네이션 관리가 첫 번째다. LLM이 위키 페이지를 작성하면서 소스에 없는 내용을 추가하는 경우가 간혹 발생한다. /lint가 소스 간 모순은 잡아주지만, 소스에서 벗어난 내용까지 완벽하게 걸러내지는 못한다. Atlan의 분석에서도 이 점을 지적하는데, RAG의 일시적 할루시네이션과 달리 위키에 한번 잘못 기록된 내용은 이후 생성에도 영향을 미칠 수 있다. 이 부분을 어떻게 잡을지가 핵심 과제다.
분류 체계의 확장이 두 번째다. 현재 엔티티와 컨셉이라는 두 축으로 분류하고 있는데, 48개 엔티티가 더 늘어나면 세밀한 그룹핑이 필요해진다. 좀 더 위키스러운 카테고리 체계를 어떻게 설계할지 고민 중이다.
인사이트 추출이 세 번째다. 지금은 지식을 구조화하고 질문에 답하는 데까지 왔다. 다음 단계는 연결된 지식들을 기반으로 새로운 인사이트를 자동으로 뽑아내는 것이다. 예를 들어, 서로 다른 엔티티에서 발견되는 공통 패턴이나 컨셉 간의 숨겨진 관계를 찾아내는 식이다.
확장 가능성은 충분히 보인다. 웹 정보나 PDF 외에도 회의록, 사내 문서 같은 소스를 넣으면 목적별로 별도의 위키를 구축할 수도 있다. 개인 학습용, 프로젝트용, 팀 지식용으로 분화시키는 것도 가능하다.
시작하는 법
Obsidian에 노트를 쌓아두고 있지만 정작 활용하지 못하고 있다면, LLM Wiki를 시도해볼 만하다. 처음부터 모든 노트를 넣을 필요는 없다. 관심 있는 주제 하나를 골라서 소스 5~10개로 시작하는 걸 추천한다.
당장 해볼 수 있는 한 가지. Karpathy의 llm-wiki gist를 열고, Claude Code에 “이 프롬프트를 참고해서 내 Obsidian 볼트에 LLM Wiki를 구성해줘”라고 말해보는 것이다. 나머지는 AI가 알아서 한다.